Acide ribonucléique de transfert
Les acides ribonucléiques de transfert, ou ARN de transfert ou ARNt, sont de courts ARN, longs de 60 à 100 nucléotides[1], qui interviennent lors de la synthèse des protéines dans la cellule. Ce sont des intermédiaires clés dans la traduction du message génétique et dans la lecture du code génétique. Ils apportent les acides aminés au ribosome, la machine cellulaire responsable de l'assemblage des protéines à partir de l'information génétique contenue dans l'ARN messager. Les cellules vivantes contiennent quelques dizaines de sortes d'ARNt, chacune d'elles étant spécifique de l'un des acides aminés. Les ARNt se terminent du côté 3' par une extrémité simple-brin conservée -CCA constante. L'acide aminé est accroché par une liaison ester sur le ribose de l'adénosine terminale de cette extrémité.
Sommaire
1 Description des ARN de transfert
2 Rôle dans la traduction du message génétique
3 Autres rôles des ARNt
4 Structure des ARNt
4.1 Nucléotides modifiés
5 Synthèse
6 Codon, anticodon et décodage
7 ARNt et aminoacyl-ARNt synthétase
8 Historique
9 Notes et références
10 Voir aussi
10.1 Articles connexes
10.2 Liens externes
Description des ARN de transfert |

Figure 1 : Schéma de l'ARNt : α, anticodon (3 nucléotides) ; β, site de fixation de l'acide aminé ; γ, boucle variable ; δ, branche D ; τ, branche T ; A, boucle de l'anticodon ; D, boucle D ; T, boucle T
Les ARNt sont des acides ribonucléiques simple brin, longs d'environ 76 à 90 nucléotides, que l'on trouve dans le cytoplasme ou dans les organites des cellules vivantes. Ce sont des ARN non codants, transcrits à partir de gènes codés dans le génome. Ils se replient pour adopter une structure complexe comportant plusieurs tiges-boucles dont la structure secondaire (2D) s'organise en "feuille de trèfle". En trois dimensions, cette feuille de trèfle adopte ensuite (en raison des interactions entre les différentes régions de l'ARNt et les contraintes imposées par les structures secondaires) une forme en L[2].
Les ARNt sont ainsi constitués de cinq régions:
- la tige acceptrice (bêta sur le schéma), sur laquelle l'acide aminé correspondant à l'ARNt est estérifié,
- la tige-boucle de l'anticodon (A sur le schéma), qui reconnaît et s'associe aux codons de l'ARN messager,
- le bras du D (D, sur le schéma)
- le bras du T (T sur le schéma)
- la région variable (gamma sur le schéma), qui peut avoir des tailles variables selon les types d'ARNt.
Rôle dans la traduction du message génétique |
Leur fonction dans la cellule est d'assurer la correspondance entre l'information génétique portée par l'ARN messager et les acides aminés contenus dans la protéine codée par cet ARN messager (ARNm). Ils sont les acteurs clés de la traduction du code génétique.
Les ARNt portent l'un des 20 acides aminés attaché par une liaison ester à leur extrémité 3'-OH (β sur la figure 1) et transportent celui-ci au ribosome. Lorsqu'ils sont ainsi porteurs d'un acide aminé, on dit que ce sont des aminoacyl-ARNt. Il y a 20 acides aminés canoniques dans le code génétique, et il existe 20 familles d'ARNt isoaccepteurs (ayant la capacité d'accepter un même acide aminé).
Dans une boucle située à l'autre extrémité de la molécule (α sur la figure 1), se trouve une séquence de trois nucléotides, spécifique de l'acide aminé, appelée l'anticodon. L'anticodon s'apparie au codon sur l'ARN messager assurant ainsi la correspondance entre codon et acide aminé, conformément au code génétique.
Dans la cellule, les ARNt aminoacylés, c'est-à-dire portant un acide aminé estérifié sur leur extrémité 3' (aminoacyl-ARNt), s'associent systématiquement en complexe avec le facteur d'élongation EF-Tu (chez les bactéries) ou EF-1a (chez les eucaryotes), lui-même complexé au GTP. C'est ce complexe ARNt:EF:GTP, appelé complexe ternaire, qui se lie dans le site A du ribosome, pour former une interaction codon-anticodon avec l'ARNm. Le ribosome vérifie la complémentarité des bases de l'ARNm et de l'aminoacyl-ARNt, puis déclenche l'hydrolyse du GTP lié à EF-Tu. Lorsque celle-ci est réalisée, le ribosome catalyse l'allongement de la chaîne protéique en cours de synthèse (réaction de transpeptidation) et avance sur l'ARN messager. L'ARNt utilisé quitte le ribosome déacylé (avec une extrémité 3'-OH), à l'état libre.
Il est alors rechargé par une enzyme spécifique, appelée aminoacyl-ARNt synthétase, qui catalyse l'estérification de l'acide aminé spécifique. Dans la plupart des espèces vivantes, il existe en général 20 aminoacyl-ARNt synthétases, une pour chaque acide aminé.
Autres rôles des ARNt |
En plus de leurs fonctions comme vecteurs des acides aminés dans le mécanisme de traduction des protéines, certains ARNt participent à d'autres processus biologiques. Certains ARNt sont utilisés comme amorces par des transcriptases inverses de rétrovirus ou de rétrotransposons, pour démarrer la synthèse d'un brin d'ADN à partir d'un brin ARN. Le VIH, virus du sida, détourne ainsi l'un des ARNt de la cellule infectée, l'ARNtLys3, pour démarrer son processus de réplication. Le génome viral contient en effet une région complémentaire de cet ARNt cellulaire.
Les ARNt aminoacylés peuvent aussi participer à certaines réactions du métabolisme secondaire, via l'action d'enzymes spécifiques appelées aminoacyl-ARNt transferases, qui catalysent le transfert de l'acide aminé estérifié sur un accepteur protéique ou peptidique. Ces réactions se font indépendamment du ribosome, d'ARNm et sans hydrolyse de GTP. Il peut s'agir de modifications post-transcriptionnelles de protéines, ou bien de synthèse non-ribosomique de peptides bioactifs.
Structure des ARNt |

Figure 2 : vue tridimensionnelle : site de fixation de l'acide aminé en jaune ; branche D en grenat ; boucle de l'anticodon en bleu, anticodon en gris ; boucle T en vert
La plupart des ARNt ont une structure canonique, conservée chez toutes les espèces. Ils se replient sur eux-mêmes, formant des appariements intramoléculaires de nucléotides pour donner une structure à quatre tiges ou bras, appelée "feuille de trèfle" (figure 1). La tige supérieure, qui porte les extrémités 5' et 3' s'appelle le bras accepteur, car c'est lui qui porte (accepte) l'acide aminé. La tige inférieure, terminée par la boucle de l'anticodon s'appelle bras anticodon, les deux autres tiges s'appellent bras T et bras D (figure 1), car ils portent des ribonucléotides modifiés, autres que A, G, C et U : la ribothymidine (T), pour le bras T et la dihydrouridine (D) pour le bras D.
Ces quatre tiges se replient en trois dimensions pour former une structure en forme de "L" (figure 2)[3]. Celle-ci résulte de l'empilement coaxial deux à deux des tiges : le bras T sur bras accepteur et le bras anticodon sur le bras D. Cette structure en forme de "L" est stabilisée par des interactions entre la boucle T et la boucle D qui font intervenir des nucléotides modifiés, que l'on retrouve conservés dans la plupart des ARNt.
L'extrémité 5' ne présente qu'un seul phosphate. L'extrémité 3' comporte quatre nucléotides non appariés et se termine toujours par le trinucléotide CCA, dont l'adénosine terminale porte la fonction OH où est estérifié l'acide aminé.
Nucléotides modifiés |
Les ARNt se caractérisent par la présence d'un grand nombre de nucléotides non-canoniques, ou nucléotides modifiés, dans leur structure. Ces modifications de nucléotides : méthylation, isomérisation, thiolation, réduction... sont incorporées post-transcriptionnellement par des enzymes spécialisées.
On trouve deux grandes classes de nucléotides modifiés dans l'ARNt : ceux qui participent à l'établissement de la stabilisation de la structure tridimensionnelle, par exemple la ribothymidine et la pseudouridine dans la boucle T, et ceux qui sont localisés dans la boucle de l'anticodon et qui interviennent directement dans l'interaction avec l'ARNm et dans la lecture des codons, comme l'inosine, la 2-thiouridine[4] ou leurs dérivés.
Certaines modifications de nucléotides sont très simples : ajout d'un groupement méthyle (CH3) et d'autres sont très complexes et nécessitent l'intervention de plusieurs enzymes. On trouve à la fois des modifications des riboses, et des modifications des bases, parfois combinées. En tout, près d'une centaine de types de nucléotides modifiés différents ont été décrites dans les ARNt des différentes espèces vivantes[5].
Synthèse |
Les ARNt sont synthétisés par transcription à partir de gènes situés dans l'ADN génomique et mitochondrial. Chez les bactéries, on trouve fréquemment plusieurs ARNt regroupés sous forme d'opérons[6] qui sont transcrits sous forme d'un seul précurseur qui est ensuite clivé. Chez les eucaryotes, les ARNt sont spécifiquement transcrits par l'ARN polymérase III.
Le transcrit primaire est en général maturé par un certain nombre d'enzymes qui clivent les extrémités. La ribonucléase P mature l'extrémité 5', et plusieurs ribonucléases sont impliquées dans la maturation du côté 3'. Une enzyme spécifique, l'ARNt nucléotidyl-transférase ou "CCAse" intervient ensuite pour ajouter ou réparer l'extrémité 3' qui se termine par la séquence CCA.
Les ARNt subissent alors plusieurs étapes de modifications de nucléotides et éventuellement l'épissage d'introns que l'on observe parfois dans certains ARNt eucaryotes.
Codon, anticodon et décodage |
Lors du processus de traduction, les trois bases de l'anticodon de l'ARNt s'apparient au codon de l'ARNm. L'interaction entre le premier nucléotide de l'anticodon et le troisième nucléotide du codon est souvent un appariement non-canonique, appelé paire wobble ou "bancale", différente d'un appariement Watson-Crick classique (A-U ou G-C). Cet appariement implique parfois un nucléotide modifié de l'ARNt.
Ces appariements wobble permettent de réduire le nombre d'ARNt nécessaires à la traduction du code génétique, en autorisant la lecture de différent codons synonymes par un seul et même ARNt. Ainsi, l'ARNt spécifique de l'isoleucine chez la souris a un anticodon IAU, où I est une inosine qui peut s'apparier aux trois codons AUU, AUC et AUA, en formant des paires I-U, I-C et I-A.
ARNt et aminoacyl-ARNt synthétase |
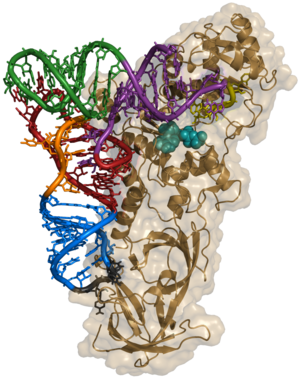
ARNt complexé avec son aminoacyl-ARNt synthétase
L'estérification de l'acide aminé spécifique à l'extrémité 3'-OH de l'ARNt est une étape clef du décodage du code génétique. On appelle cette étape l'aminoacylation et, dans toutes les cellules vivantes, il existe une vingtaine d'enzymes, les aminoacyl-ARNt synthétases, dont la fonction est de catalyser cette étape.
Chacune de ces enzymes est spécifique d'un acide aminé donné et reconnait le ou les ARNt correspondant. Ces enzymes sont capables de discriminer les ARNt spécifiques de son acide aminé, en reconnaissant des motifs de nucléotides particuliers, souvent dans l'anticodon lui-même, mais parfois dans d'autres régions de l'ARNt. Cette reconnaissance est cruciale, car il n'y a plus de contrôle qualité ultérieur au niveau du ribosome : toute erreur dans l'aminoacylation se traduira donc ensuite par une erreur dans le décodage du message génétique.
L'aminoacylation comprend deux étapes: l'activation de l'acide aminé par adénylylation et la formation du lien ester entre l'acide aminé et l'hydroxyle 2' ou 3' du ribose du nucléotide 3' de l'ARN de transfert[7].
La première étape consiste en l'attaque nucléophile de l'acide aminé sur une molécule d'ATP reconnue par l'aminoacyl-ARNt synthétase. L'oxygène de cet acide aminé brisera le lien entre le premier et le second des trois phosphates de l'ATP. Ainsi, il se formera un nouveau lien, un lien anhydride, entre l'acide aminé et l'AMP (adénosine monophosphate) ainsi généré. L'acide aminé est ainsi activé sous forme d'aminoacyl-adénylate, qui reste lié à l'enzyme.
La deuxième étape consiste en la catalyse du transfert de l'acide aminé activé sur le 2'-OH ou le 3'-OH du ribose terminal de l'ARNt. En utilisant l'énergie contenue dans l'aminoacyl-adénylate, l'extrémité -OH de l'ARN de transfert effectue une attaque nucléophile sur l'acide aminé. Le transfert aboutit à la création d'un lien ester qui est encore riche en énergie.
Après ces deux étapes, l'ARN de transfert est prêt à apporter son acide aminé spécifique vers le ribosome et l'ARN messager[8].
Historique |
L'existence des ARNt, comme « adapteurs » entre les acides aminés et l'ARN messager, a été postulée par Francis Crick[9], avant que ceux-ci ne soient effectivement découverts par Hoagland et Zamecnick en 1958[10]
C'est également Francis Crick qui a formulé l'hypothèse de « l'interaction bancale » ((en) wobble hypothesis) qui permet d'expliquer le fait qu'un ARNt donné puisse lire plusieurs codons synonymes[11].
Notes et références |
S. J. Sharp, J. Schaack, L. Cooley et D. J. Burke, « Structure and transcription of eukaryotic tRNA genes », CRC critical reviews in biochemistry, vol. 19, no 2, 1985, p. 107–144 (ISSN 0045-6411, PMID 3905254, lire en ligne, consulté le 11 mai 2018)
Jeffrey M. Goodenbour et Tao Pan, « Diversity of tRNA genes in eukaryotes », Nucleic Acids Research, vol. 34, no 21, 2006, p. 6137–6146 (ISSN 1362-4962, PMID 17088292, PMCID PMC1693877, DOI 10.1093/nar/gkl725, lire en ligne, consulté le 11 mai 2018)
(en) J.D. Robertus, J.E. Ladner, J.T. Finch, D. Rhodes, R.S. Brown, B.F. Clark et A. Klug, « Structure of yeast phenylalanine tRNA at 3 A resolution. », Nature, vol. 250, 1974, p. 546–551 (PMID 4602655), (en) S.H. Kim, F.L. Suddath, G.J. Quigley, A. McPherson, J.L. Sussman, A.H. Wang, N.C. Seeman et A. Rich, « Three-dimensional tertiary structure of yeast phenylalanine transfer RNA. », Science, vol. 250, 1974, p. 546–551 (PMID 4601792)
R K Kumar et D R Davis, « Synthesis and studies on the effect of 2-thiouridine and 4-thiouridine on sugar conformation and RNA duplex stability. », Nucleic Acids Research, vol. 25, no 6, 15 mars 1997, p. 1272–1280 (ISSN 0305-1048, PMID 9092639, PMCID 146581, lire en ligne, consulté le 13 novembre 2016)
Anna Czerwoniec, Stanislaw Dunin-Horkawicz, Elzbieta Purta et Katarzyna H. Kaminska, « MODOMICS: a database of RNA modification pathways. 2008 update », Nucleic Acids Research, vol. 37, no Database issue, 1er janvier 2009, D118–121 (ISSN 1362-4962, PMID 18854352, PMCID 2686465, DOI 10.1093/nar/gkn710, lire en ligne, consulté le 10 novembre 2016)
(en) Maurille J. Fournier et Haruo Oseki, « Structure and organization of the transfer ribonucleic acid genes of Escherichia coli K-12 », Microbiol. Rev., vol. 49, 1985, p. 379-287 (PMID 2419743)
(en) M. Ibba et D. Söll, « Aminoacyl-tRNA synthesis », Annu. Rev. Biochem., vol. 69, 2000, p. 617-650 (PMID 10966471)
H. Lodish, A. Berk, P. Matsudaira, C.A. Kaiser, M. Krieger, M.P. Scott, L. Zipursky et J. Darnell, Biologie moléculaire de la cellule, Bruxelles, de Boeck, 2005, 3e éd. (ISBN 978-2804148027)
(en) Francis H. Crick, « On protein synthesis », Symp. Soc. Exp. Biol., vol. 12, 58, p. 138-163 (PMID 13580867, lire en ligne)
(en) M.B. Hoagland, M.L Stephenson, J.F. Scott, H.I. Hecht et P.C. Zamecnik, « A soluble ribonucleic acid intermediate in protein synthesis », J. Biol. Chem., vol. 231, 1958, p. 241-257 (PMID 13538965)
(en) F.H. Crick, « Codon--anticodon pairing: the wobble hypothesis. », J. Mol. Biol, vol. 19, 1966, p. 548-555 (PMID 5969078)
Voir aussi |
Articles connexes |
- ARN
- ARN messager
- ADN
- Une liste des différents types d'ARN
- Liste d'abréviations de biologie cellulaire et moléculaire
Liens externes |
(en) Compilation des séquences d'ARNt à l'Université de Bayreuth
(en) G~tRNA~db: The Genomic tRNA Database
(en) tRNAdb
 Portail de la biologie cellulaire et moléculaire
Portail de la biologie cellulaire et moléculaire


